Some two, maybe three years ago, I've stopped using the so called 'dark mode' on my computers.
Having a strong light (aka The Sun) from behind made the monitor with a dark backgrounds a mirror, so it was more a case of light mode being forced me on that anything else.
But it it grew on me, and now I see no reason to use a dark theme anywhere.
It looks better, it feels better, it is better.
Then I've discovered joshua stain and his monochrome color theme.
It looked cool, and why not?
There was a ready emacs theme - almost mono.
And again, the experiment was a success: bolds, italics are all I need to not feel lost.
Having a full rainbow on the screen was yet another distraction I didn't need.
So I used the white variant of almost-mono, since the cream variant was not to my linking.
The colors used in that theme became a nuisance.
Why should my string be green?
Why is notmuch a rainbow?
Time to go my own way.
I didn't want to copy jcs's theme 1 to 1, so I tried to create a new theme from scratch.
I ended with a cream color scheme, so task successfully failed
Emacs makes making themes a breeze: just M-x customize-create-theme and you can modify the faces with a few clicks:
Since I used only two colors:
#f2ebd6 as the light color, and
#352f19 as the dark one
There was very little decisions to be made.
I just went though the faces I've encountered and set them to use those colors.
If I see a new face, I can easily add it to the theme and voila - one more place with less chaos in my life.
All hail the cream.
All hail the cremacs.
Guess I'll update color scheme of this site sometime soon.
The web is mind-bogglingly massive. So massive, in fact, that it’s nearly impossibly to visualize its true scale. Even if your entire lifetime was spent perusing the web and searching every nook and cranny, you would never reach more than a miniscule fraction of the vast ocean of information available to you.
There is so much information in the world that “post-scarcity” is a severe understatement of the scale of our information age.
To have any hope of meaningfully browsing the web, we need systems in place that artificially limit that scope—curation technologies. Today, the web curation process is almost entirely through search engines and social media algorithms, commercial automated systems to narrow our focus on the web to the specific things we know we want.
Before search engines, though, existed older, more powerful discovery methods, curated by humans for our benefit; these systems and networks still exist, but they seem hidden from the view of the mainstream web.
Let’s take a look at the secret web, the festival of personal expression and idea sharing happening below the surface, out of the mainstream view, spearheaded by people like you and me.
Many Names, One Network
Outside the grasp of social media and the commercial web sits a broad community of people with personal websites and blogs, interacting with and following each other without trying to make money or become famous.
This community has received many names, each trying to capture a different side of the network.
The Small Web contrasts this community with the “Big Web”, valuing personal ownership over scale.
The IndieWeb also values personal ownership of websites, providing numerous technical standards and proposals to help facilitate interaction between different people’s blogs.
Web 1.0 rejects the hype of “Web 2.0” apps, using simple, straightforward technologies to build websites.
The Blogosphere is an old term that’s been around since 1999, referencing the community of bloggers.
The Web Revival is the concept shared by many that this community has been growing and making a comeback.
Whatever the form, this idea keeps coming back; something appeals to many about the idea of a smaller, more personal web, made up of connections between real people, without corporate interests.
I call this a “network” because it truly is one; this community of sites has developed many, many ways for readers to discover more of it, and they all revolve around the hyperlink.
The Link Graph
The most fundamental innovation of the world wide web as a medium is hypertext (HTTP, for example, stands for “HyperText Transfer Protocol”). Hypertext, put simply, is text that links to other pages. This is the fundamental technology that ties together the web: every method of discovering sites, other than word of mouth, relies on links between webpages.
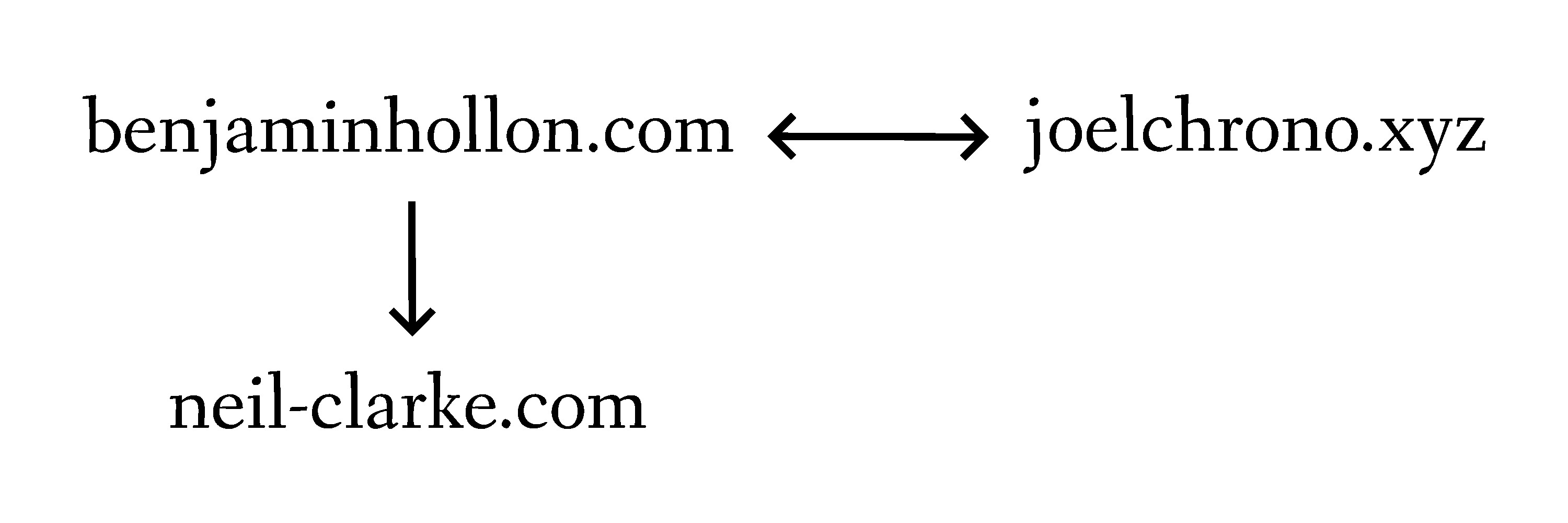
To really understand how these methods work, we need to understand the link graph. Let’s construct a very tiny subset of the web, made up of just three websites:
Joel and I link to each other’s sites fairly frequently; we talk often and inspire each other. This link is bidirectional.
While Joel and I both are subscribers to Clarkesworld, I’m the only one who links to Neil Clarke’s blog on my site. Neil Clarke, of course, probably has never encountered my site, so this link is one way.
This relationship makes for a simple chart
This is a very simple example of a link graph, a representation of how various sites link to each other. The more sites you look at, the more complicated it gets; search engines internally graph this relationship between hundreds of thousands, millions, or even billions of sites.
Given a graph like this, it’s possible to find out how similar sites are, decide which sites are the most important or official (one of Google’s key innovations), or predict how a random person surfing the web might discover websites. This concept of the link graph is the most central tool in any analysis of relationships on the web.
The big difference between the secret web and the large, messy corporate web is that people on it frequently link and reply to each other’s websites and blog posts, creating a compact network of people with related ideas and interests, while on the corporate web companies profit from keeping you on their site and link outwards begrudgingly. This allows projects like IndieMap, a link graph of 2,300 sites on the Indie Web and their relationships to each other.
Classic Web Discovery: Blogrolls, Link Blogs, and Webrings
Now that we understand the importance of links to discovery on the web, let’s examine some classic tools for discovering new sites on the web without search engines.
One powerful tool is the blogroll—many personal websites have a list of other sites the author finds interesting. This “blogroll” lets readers who enjoy one site easily find a curated list of other sites they’ll enjoy. I have a blogroll, where I link to all the sites I most closely follow. Many of the blogs I link to also have their own blogrolls, often larger than mine, providing almost endless opportunity to discover new, fascinating people.
A tool for discovering sites I’ve personally been enjoying lately is the link blog. Link blogs can either be their own dedicated sites or within a larger blog; the idea is a regular post that links to and comments on interesting articles and webpages the author encountered recently.
One famous (and fantastic) example is Pluralistic, a daily link blog by Cory Doctorow focused largely on topics such as digital privacy, monopolistic practices by big tech, environmental sustainability, and right to repair. A recent favorite of mine is Scrolls, by Mike Sass, a weekly roundup of fascinating posts and projects from the IndieWeb and Fediverse.
Everything old is new again, and webrings are no exception. A webring is a collection of sites who all agree to link to each other in a sort of loop; each site links to two neighbors, and by following the links you reach every site in the ring. Some excellent current examples are the IndieWeb Webring, Fediring, and Polyring (which I designed the logo for). Often, web rings have a theme, letting people browsing easily surf through many related websites.
And of course, no discussion of discovery on the web would be complete without mentioning web feeds such as RSS and Atom, a spam-proof, simple way to subscribe to sites we love to hear about new updates. About Feeds is a great introduction, if you’re not already familiar with them.
The Danger of Search Engines
While all of those wonderful methods for discovering the secret web exist, it’s time to mention the elephant in the room: search engines.
The selling point of a search engine is essentially to remove the need for you, the reader to worry about the link graph; when you’re looking for something specific, you can quickly find it without needing to browse numerous websites to get to what you need.
Search engines are extremely valuable tools, but also bring dangers, if you let them be your only discovery tool.
Remember, the web is unimaginably big: you will never see all of it. Any search engine you use will, by necessity, show you a subset of information out there, and the designers have to make decisions about what to value. When a search engine is your sole source of information, you give it full control over what parts of the web, what voices and opinions, even exist for you.
With a corporate search engine like Google, that means giving a commercial entity whose main interest is monetary full control over the ideas you receive. From an epistemology standpoint, that should terrify you.
Even when you start looking at alternate search engines, it’s important to realize that many, such as DuckDuckGo and Ecosia, use the corporate engines’ indexes, under the hood. Mojeek’s Search Engine Map is a good visualization of which engines use their own indexes and which use big tech sources. Seirdy’s article on search engines with independent indexes is also a fantastic resource.
All that to say, a search engine cannot be your sole source of information and discovery. Its strength is in helping you find specific things when you need them, but for a well-rounded information gathering experience, we all need to put more faith into other discovery methods, especially for the independent, secret web.
First, I of course am developing an independent search engine that focuses on the small, independent web, Clew. Right now, many others are doing the same or similar:
Marginalia - This is my favorite independent search engine right now, and the one I use the most often.
Unobtanium - The developer and I frequently chat about our work and bounce ideas off of each other.
Stract - This one launched around the same time as Clew; I haven’t looked too close, though.
Lieu - A search engine aimed at searching webrings. Very cool mix of old and new discovery methods!
Mwmbl - A user-curated search engine, a fascinating experiment.
Search My Site - Very similar in goals to Clew, but only crawls user-submitted sites instead of trying to discover new sites.
Wiby - A search engine for websites using older technology, great for use on vintage computers.
PeARS - A search engine that can be run in the browser, without needing a server. I love the concept, and I’m looking forward to seeing it develop.
Mojeek - Probably the biggest of the independent search engines; they’ve been around forever.
I’ve also been noticing a few cool new takes on older discovery technologies, many of which I’m considering integrating in some way into Clew. OPML, a format that can list RSS feeds, has a relatively recent proposal for auto-discovering machine-readable blogrolls, which would be interesting to integrate into crawler code to better find which links on a page are valuable to the site’s creator.
James has been developing a feed reader, Artemis, and most interesting is a recent integration, Artemis Link Graph, a browser extension that will tell you when a page you’re reading has been linked to by sites you follow. This is an excellent use of the concept of the link graph, and it would be interesting to integrate this concept into a search engine; perhaps users could specify sites they trust, and the search engine could weight or highlight results appropriately, based on where those sites link?
I have a few other ideas of my own, and my redesign of Clew has had excellent progress in the last month, so I’m excited to get to publish those ideas relatively soon, probably this summer. It’s a bright world we’re moving into, with amazing ideas for discovering new sites.
Preserving and Growing the Secret Web
So, we’ve examined how the secret web works, looking at how readers discover new sites and even considering some new, promising ideas. Where do we go next?
The Secret Web is exciting, and it’s unlikely that it can ever be killed, but it needs intention and attention to really thrive.
Thankfully, many people are working on the technology side of this; the IndieWeb, particularly, is spearheading developing wonderful technology for growing and connecting personal websites.
With the technical side taken care of, we should consider the social side: much of the independent web today is made up of people with similar interests, in technology in particular. We need to look to lowering the barrier to entry and expanding access to this web. We need to make this web an open secret.
There are two sides to this: making it easier to learn to create websites and easing discovering websites. In the past, I worked on readable.css, to ease making beautiful and accessible sites. Now, I’m working on Clew, to make discovering what real people think easier.
That’s really Clew’s mission: when you look something up, you’re not trying to get to an “official” source of information, you’re looking for blog posts or fan pages about the topic. Very early after releasing Clew, when results were worse than they are today (and, hopefully, much worse than where they will be soon), the feedback I received was still overwhelmingly positive: even though people weren’t getting the results they’d hoped for, the sites they did find were fascinating and ones they hadn’t seen before.
So, what can you, the person reading this do? If you have a website, fantastic! Maybe write some more code towards it, or draft a blog post if you haven’t done so in a while.
If you think starting a website sounds like fun, you should give it a go! There are very many resources out there. A good starting place is my own guide to blogging on a budget, where I look at options to have a very personal site without breaking the bank, or even for free.
Recently I watched a few videos about how programmers back in the early days of video gaming, as well as demo coders today developing for old hardware, were using every trick in the book (and quite a few tricks that weren't in any books) to make video games and demos as visually appealing and interesting as they possibly could and to make it appear as if the hardware was doing things that it shouldn't technically be able to do.
Here are a few examples of videos to illustrate what I mean:
In order to make these games and demos look the way they do, the coders had to write highly optimised code in assembly language that often needed to be accurate down to the individual clock cycle of the CPU because some events have to occur at the exact right time for the effect to look good. On CRT displays, for which these devices are designed for, the screen is drawn from top to bottom with an electron beam. For some effects to look right, the content of the video buffer, which holds the image that is drawn on the screen, needs to be manipulated while the image is being drawn on the screen, which requires very precise timing.
This got me thinking that optimising code and writing lean and resource-efficient code in the first place seems to be a dying art. It's still necessary for programming embedded devices which typically have a very limited amount of program memory, RAM and processing power, but PCs (and Macs) these days have almost unlimited processing power and memory compared with the systems of the past. Terabytes of drive space, gigabytes of memory and clock speeds measured in gigahertz, not to mention multicore CPUs with 8 or more cores on a single chip would have blown every 80s programmer's mind; they would have had no idea what to do with this any more than I would know what to do if somebody landed a spaceship in front of my house and handed me the keys.
But not to fear, coders have found ways to use all these resources by writing gigantic applications that require huge amounts of disk space, RAM and processing power and still manage to feel slow even on high end computers. I get to enjoy the full Microsoft 365 experience at work with Windows 11, Outlook, Teams, Sharepoint, the entire office suite and on and on, and even on a powerful machine all of this just feels way more sluggish than it should. If I installed a copy of Windows 7 with contemporary versions of Outlook, Office and Skype on this computer, it would absolutely fly and I could do everything I'm doing now, but faster. I mean, even just a right click on the desktop sometimes takes an entire second before the menu appears. That doesn't seem to me like there's particularly well written code running behind it. Microsoft's CEO agrees ;)
Ok, I'm starting to rant now. My point is, programmers these days (and I'm including myself in this too) might do well to occasionally take some inspiration from coders of the past or demoscene coders and after implementing something, take a moment to look over their code and ask themselves "is there maybe a more efficient way to do this". Because chances are there is, and at the end of the day a lean and well optimised codebase is something that everybody benefits from. Unfortunately it seems that with the advent of AI assistants and vibe coding we're moving further and further from this idea, but one can hope...